
Die meisten Umgebungen, in denen UCS im Einsatz ist, bewegen sich im Bereich von einigen Dutzend Usern bis zu einigen Tausend – Größenordnungen, die direkt mit der Standardkonfiguration von UCS umgesetzt werden. In den von Schulträgern betriebenen Systemen gibt es einen Sprung auf einige 10.000 bis zu 100.000 User – hier sorgen die Konzepte von UCS@school für eine funktionierende Skalierung.
Rechnet man Gruppen, Rechner und andere Infrastrukturobjekte im LDAP ein, erreichen diese Umgebungen kaum mehr als 200.000 Objekte. Was aber passiert, wenn in einer Umgebung mehr als 30.000.000 Objekte im LDAP verwaltet werden sollen?
Die Rahmenbedingungen
Bereits 2014 begann ein Projekt, in dem sich Univention genau mit dieser Frage beschäftigt. Verwaltet werden sollen 30.000.000 Accounts (vergleichbar mit dem „simple authentication account“ im Univention Directory Manager), ergänzt um zahlreiche, weitere Parameter. Diese Accounts dienen als Benutzerverzeichnis für Mail- und Groupware-Services auf Basis von Dovecot und Open-Xchange. Wie in dieser Größenordnung nicht überraschend, unterliegt eine solche Umgebung einer hohen Last: Mehrere Millionen Logins und mehrere Tausend Änderungen müssen pro Stunde verarbeitet werden.
Die erste Frage – Geht das überhaupt?
Noch vor dem richtigen Start des Projekts stand die grundlegende Frage: Geht das mit UCS? Geht das überhaupt mit OpenLDAP?
Damals wurde diese Frage noch mit UCS 3.2 geprüft – UCS 4.0 war noch nicht released. Die ersten Tests zeigten: Die notwendige Performance ist erreichbar, mit UCS 3.2 aber nur knapp. Der Flaschenhals damals war das „BDB“ Backend von OpenLDAP. Bedenklich war dabei nicht nur, dass die Standard-Konfiguration im Produkt für die Größe nicht ausreichte, sondern auch, dass bei Messungen auf einem Standard-Serversystem nicht alle Werte überzeugen konnten.
Zum Erscheinen von UCS 3.0 in 2011 war BDB das Standard-Backend der enthaltenen OpenLDAP-Version. Bereits zu dem Zeitpunkt wurde aber im OpenLDAP-Projekt intensiv am Nachfolger „MDB“ (Memory-Mapped-Database) gearbeitet. Während der Performance-Tests in 2014 galt das MDB-Backend als stabil. Daher war es naheliegend auch dieses Backend zu prüfen.
MDB vs. BDB – ein unerwarteter Unterschied
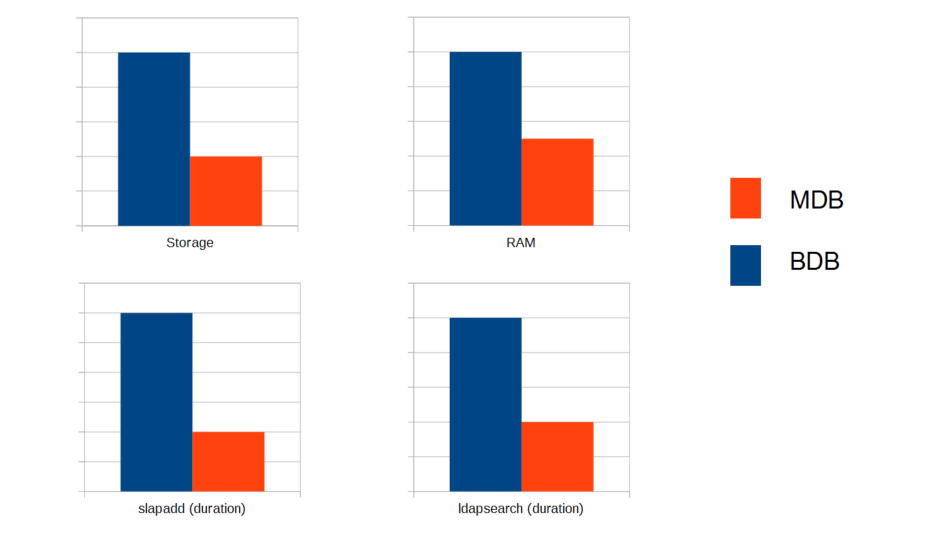
Der Performance-Unterschied zwischen MDB und BDB erwies sich als überraschend eindeutig. Während MDB beim Verbrauch von Arbeitsspeicher und Festplattenplatz nur 30%-50% von BDB benötigte, lag die Antwortzeit bei LDAP-Änderungen oder Abfragen bei nur 25%-30%. MDB ist also um den Faktor 3 bis 4 schneller als BDB. Alle Tests wurden dabei mit einer Datenbank mit 30 Millionen Objekten durchgeführt (ein LDIF von ca. 60 GB). Die Zeitmessung von LDAP-Suchen erfolgte durch einige Tausend, sequentiell ausgeführte Suchen mit LDAP-Filtern, die im Datenbank-Index lagen. Sehr positiv war dabei auch die CPU-Last: Während BDB durch das sequentielle Ausführen der LDAP-Suchen einen CPU-Core vollständig beanspruchte, lag die Steigerung der Last bei MDB im kaum messbaren Bereich. In kurzen Tests zeigte sich, dass dieses Verhalten auch bei mehr als 50 Millionen Objekten unverändert bleibt – also auch in diesem Projekt noch gut skaliert werden kann. Diese klaren Vorteile haben dazu geführt, im Projekt auf MDB zu setzen – eine Entscheidung, die auch in UCS 4.0 dazu geführt hat, dass MDB zum Default wurde.
Stolpersteine von MDB
Wie wohl immer bei der Umstellung auf eine neue Technologie gilt es auch bei MDB einige Änderungen zu beachten. Während das teilweise mühselige Tuning von Datenbankparametern, wie BDB sie in der DB_CONFIG erforderte, wegfällt, gibt es bei MDB eine sehr entscheidende Option in der slapd.conf: „maxsize“ (UCR: ldap/database/mdb/maxsize). Die hier in byte angegebene Größe definiert die obere Grenze für die Größe der MDB-Datenbank, unter UCS also der Datei /var/lib/univention-ldap/ldap/data.mdb. Dieser Wert muss in großen Umgebungen erhöht werden, im konkreten Projekt wurde mit 250GB ein deutlicher Puffer eingeplant. Wichtig beim Umgang mit dieser Datei ist zu wissen, dass es ein „sparse“ file ist. Dieses Format wird auch gerne als „thin provisioning“ im Virtualisierungsumfeld genutzt und verhält sich etwas ungewöhnlich: Während ein „ls“ auf die Datei bereits die volle maximale Größe (entsprechend „maxsize“) anzeigt, nutzt sie auf dem Dateisystem (z. B. in der Ausgabe von „df“) nur den tatsächlich benötigten Platz. Diesen Zustand erhalten jedoch nicht alle Tools. Ein einfaches „cp“ führt beispielsweise zu einer Kopie in voller „maxsize“ Größe. Damit sollte beispielsweise das eingesetzte Backup-Tool zurechtkommen. Eine weitere Besonderheit dieser Dateien ist, dass der Speicherverbrauch niemals geringer wird – werden Daten aus dem LDAP gelöscht, wird der Speicherplatz nur innerhalb der MDB-Datei als „frei“ markiert, nicht aber im Dateisystem freigegeben.
Ein in der Praxis gravierenderer Unterschied ist die I/O-Last, die MDB bei Änderungen generiert. MDB bietet hier den großen Vorteil, dass die Datenbankdatei zu jedem Zeitpunkt in sich konsistent ist. Vereinfacht beschrieben wird eine neue Version eines LDAP-Objekts bzw. dessen Attribute zunächst an einer freien Stelle in die Datei geschrieben und dann nur noch durch eine Verknüpfung von der alten auf die neue Version umgelenkt. Hierbei generiert MDB viele sehr kleine Schreiboperationen, insbesondere, wenn bei einer Änderung viele Indices aktualisiert werden müssen. Das Storagesystem muss daher mit einer großen Anzahl von IOPs (im Projekt >10.000) zurechtkommen. Werden mehrere LDAP Server, wie in virtualisierten Umgebungen üblich, auf einem gemeinsamen, netzwerkbasierten Storage angebunden, wird das schnell zum Flaschenhals. Dieses Verhalten kann durch Konfiguration abgeschwächt werden. Da dies aber das Risiko von Datenverlusten steigert, sollte davon im Standardbetrieb kein Gebrauch gemacht werden. Für einen initialen Datenimport über „slapadd“ kann die weitreichendste dieser Optionen („nosync“) aber Sinn machen – in unserem Projekt ließ sich damit die Initialisierung einer einzelnen MDB-Datenbank in unter 4 Stunden realisieren.
In der Praxis
Vorweg: Die Zahl der zu beachtenden Dinge, um UCS in dieser Größenordnung zu betreiben, ist erstaunlich gering. Das gesamte Managementsystem, also auch das Management der LDAP-Objekte im Webinterface, kommt direkt mit dieser Menge an Informationen zurecht. Voraussetzung dafür ist ein Hinterfragen der LDAP-Indices auf die in der Praxis benötigten Werte sowie ausreichend RAM auf den LDAP-Servern, um für den Zugriff auf die Indices nicht auf das Storage ausweichen zu müssen. Im Projekt schwanken die Arbeitsspeichergrößen dabei zwischen 32 und 96 GB.
Eine Umgebung für ein Projekt dieser Größenordung besteht natürlich nicht aus einem einzelnen LDAP-Server, sondern aus Dutzenden. Aufbau und Betrieb dieser Umgebung erfordern etwas mehr manuelle Eingriffe, um nicht unnötig lange Wartezeiten zu generieren. Setzte man auch bei einigen Tausend Usern einen neuen UCS LDAP-Server in einer oder in wenigen Stunden auf, würde ein Initialisieren des LDAP auf dem Standardweg des Domänenbeitritts mit 30M Objekten Tage dauern.
Beim Ausrollen eines neuen LDAP-Servers verläuft der UCS Domänenbeitritt so ab, dass der neue Server lokal eine leere LDAP-Datenbank anlegt, alle Objekte per „ldapsearch“ vom UCS Master ausliest und dann per „ldapadd“ lokal einspielt. OpenLDAP bedient einen einzelnen, lesenden Client (dies entspricht einem Prozess auf dem Server) mit grob 1.000 LDAP Objekten/Sekunde – bei dieser Umgebung benötigt das Auslesen dennoch mehr als 8 Stunden. Dafür gibt es diverse Gründe. Entscheidend ist aber, dass das Auslesen des LDAP vom UCS Master per „ldapsearch“ sowie das Einspielen der LDAP-Objekte über ein „ldapadd“ jeweils nur einen Prozess generieren und damit nicht über mehrere CPU-Kerne skalieren. Meist wartet dieser Prozess auch nur auf das Storage.
In einer Standard-Konfiguration von UCS scheitert damit der Domänenbeitritt an einem Timeout. Im Projekt wurden daher alternative Deployment-Methoden entwickelt, die entweder auf einer bestehenden MDB-Datenbank aufbauen (z.B. von einem identisch konfigurierten LDAP-Server), ein LDIF akzeptieren oder die Timeouts durch paged LDAP searches vermeiden. Je nach Verfahren dauert das Deployment eines neuen Servers so von unter einer Stunde bis hin zu mehreren Tagen.
Weiteres Feintuning ist bei einigen CRON-Jobs von UCS notwendig. Beispielsweise sollte das tägliche Backup des LDAP in ein LDIF nur auf ausgewählten Servern aktiv bleiben, andernfalls füllt sich damit sehr schnell der Plattenplatz.
Was nicht geht
Ein entscheidender Faktor für das Gelingen dieses Projekts liegt nur indirekt im LDAP: die Verwendung von „simple authentication Accounts“ bzw. davon abgeleiteten projektindividuellen LDAP-Objekten. Diese Accounts haben keine POSIX-, Samba- oder Kerberos-Attribute und keine Gruppenmitgliedschaften. Hier lauern ansonsten diverse Limitierungen; um nur einige zu nennen: sowohl POSIX (uidNumber) als auch Samba (SID) nutzen numerische IDs, deren Standard-Nummernkreise zu klein sind. In der Voreinstellung würden alle Accounts Mitglied der gleichen Standardgruppe – damit haben einige Client-Systeme schon bei wenigen Tausend Benutzern Probleme.
Fazit
Nach den beiden grundlegenden Entscheidungen, auf MDB als Backend von OpenLDAP zu setzen und im LDAP projektspezifische Objekte zu verwalten, hat sich die Realisierung eines Verzeichnisdienstes mit mehr als 30 Millionen Objekten mit UCS und OpenLDAP als sehr gut umsetzbar erwiesen. Diese technische Komponente war dann schnell auch nicht mehr der Fokus des Projekts, sondern die Realisierung der darauf aufbauenden Logik zur Pflege der Accounts.


Kommentare
Ardekay
Ein sehr aufschlussreicher Artikel, vielen Dank!
Moritz Bunkus
In der Tat sehr interessant und beeindruckend.
Gab es bei dieser Fülle von Änderungen denn keine Probleme mit dem Listener-/Notifier-Mechanismus? Immerhin werden sämtliche LDAP-Änderungen protokolliert; allein schon diese Datei dürfte unhandlich groß werden.
Ingo Steuwer
Wir haben uns die notifierID und die Größe der „transaction“-Files auch vorher angesehen – mit der gleichen Sorge. Unseren Berechnungen nach erreicht man hier auch nach Jahren kein hartes Limit, die notifierID dürfte mindestens 20 Jahre wachsen. Das „transaction“ File könnte man bei dieser Größe in der Tat alle paar Monate kürzen, wie ist hier beschrieben: http://sdb.univention.de/1296
Die Größe der Datei wirkt sich aber nur negativ aus wenn UCS-Systeme sehr weit in der Replikation „zurück hängen“.
Moritz Bunkus
Ah. Das ergibt Sinn 🙂